Stable Diffusion is great at taking source images and applying a style to them. In this example, I turn Google Maps into anime background style by taking a section of my screen as input. I then set it to generate an image when a change is detected.
ComfyUI is a node-based GUI for Stable Diffusion. I like ComfyUI because of my game development experience with node editors (Unreal Blueprints, Unity Shader Graph, Substance Designer, Blender Shader Editor). Most people who start learning Stable Diffusion go with Stable Diffusion web UI, known as Automatic1111 to avoid ambiguity. There’s also Fooocus. It’s great for generating good images quickly, but you can’t see what exactly what is happening under the hood.
ComfyUI workflow
Here is the workflow:
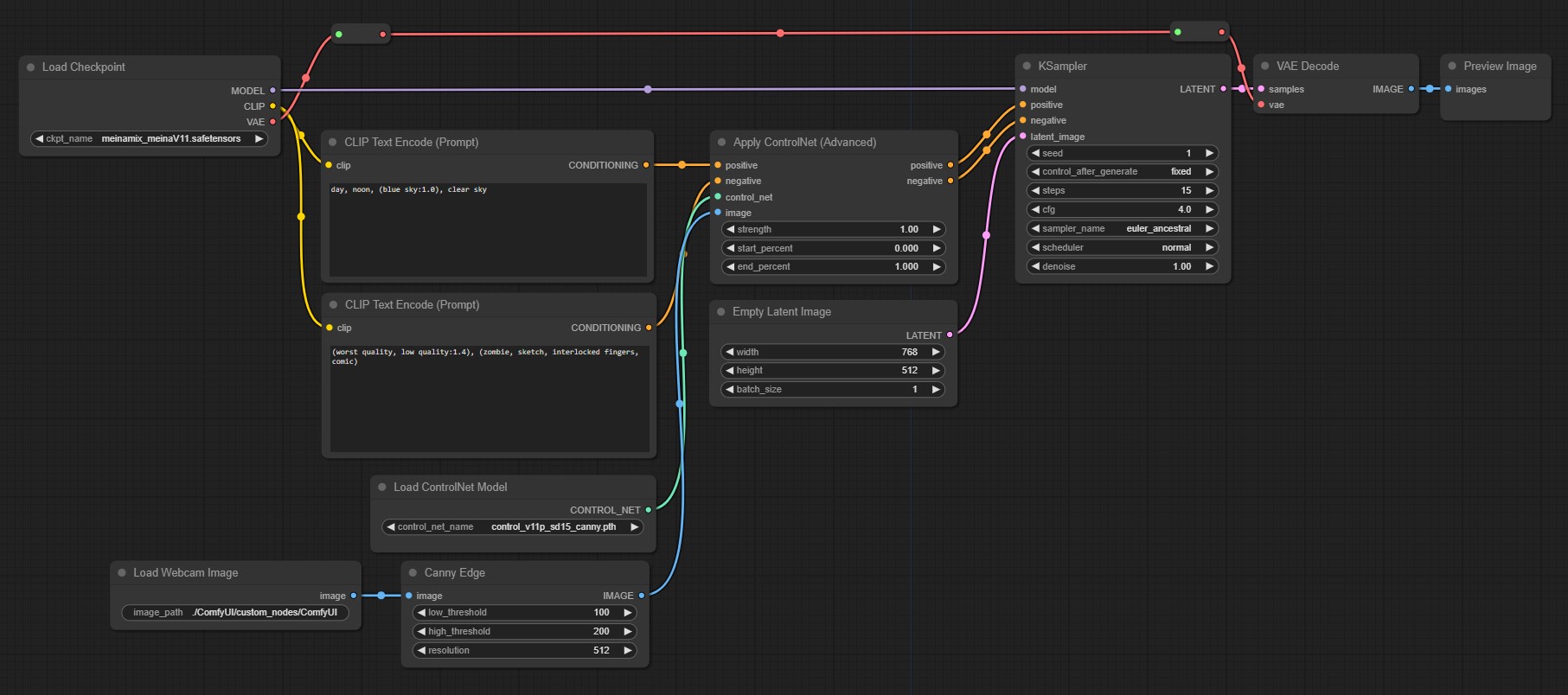
- Checkpoint model:
<a href="https://civitai.com/models/7240/meinamix">meinamix_meinaV11</a> - Positive Prompt:
day, noon, (blue sky:1.0), clear sky - Negative Prompt:
(worst quality, low quality:1.4), (zombie, sketch, interlocked fingers, comic) - Resolution:
768 x 512 - ControlNet model:
<a href="https://huggingface.co/lllyasviel/ControlNet-v1-1/blob/main/control_v11p_sd15_canny.pth">control_vllp_sd15_canny.pth</a>
Depending on the Google Maps location, I add a country or city name in the positive prompt (e.g. Japan, New York, Paris, etc.). I used toyxyz’s custom webcam node to capture a section of the screen and plug the output into a ControlNet canny model.
KSampler:
seed: 1control_after_generate: fixedsteps: 15cfg:4.0sampler_name: euler_ancestralscheduler: normaldenoise: 1.00
You might be asking, “Why didn’t you use LCM-LoRA like in the workflow in toyxyz’s example?” I tried it, but the final image was looking too similar to the webcam’s capture. I wanted it to be more creative, and modifying the prompts was not quite giving me the results I wanted.
It is possible to optimize this further and make better and faster generations. Perhaps by using StreamDiffusion, TouchDesigner, or a model based on SDXL-Lightning. Check out Félix Sanz’s articles on SDXL-Lightning comparison and Optimizing Stable Diffusion XL.