Open large language models (LLMs) are revolutionizing accessibility to artificial intelligence. They enable researchers and developers to create tailored solutions for specific requirements. Nowadays, you can run LLMs such as Llama-3-8B-Instruct on a desktop computer and obtain responses comparable to some proprietary models. In this article, let’s talk about the history of open LLMs, their use case, and how to deploy them locally.
History of Open-Source Large Language Models (LLMs)
While the roots of language models can be traced back to the 1960s, I’d like to focus on 2023. This is the year open LLMs reached an inflection point when LLaMA was leaked to the public. The open-source community quickly sprung into action and followed suit with better-performing fine-tunes. Moreover, tools were developed that allow users to run LLMs on low-end devices. This renaissance was mentioned in Google’s leaked “We Have No Moat” document. Later that year saw the release of Llama 2, Falcon 7B and 40B, Code Llama, Mistral 7B, and Mixtral 8x7B. All these were followed by corresponding fine-tunes. By the end of the year, <strong>Mixtral-8x7b-Instruct-v0.1</strong> was on par with Gemini Pro, Claude 2.1, and GPT 3.5 Turbo according to LMSYS Chatbot Arena.
Cameron R. Wolfe, Ph.D. dives deeper into the history of open-source LLMs:
- The History of Open-Source LLMs: Early Days [link] (Jul, 2023)
- The History of Open-Source LLMs: Better Base Models [link] (Jul, 2023)
- The History of Open-Source LLMs: Imitation and Alignment [link] (Aug, 2023)
It is a rapidly evolving industry. How fast? Just this past 5 months (January to May of 2024) we got:
- May 29 – Codestral 22B
- May 23 – Mistral 7B v0.3
- Apr. 24 – Mixtral 8x22B v0.1
- Apr. 23 – Phi-3
- Apr. 18 – Meta-Llama-3
- Apr. 4 – Command R+
- Mar. 28 – Jamba v0.1
- Mar. 27 – DBRX
- Mar. 17 – Grok-1
- Feb. 21 – Gemma
- Jan. 29 – CodeLlama
The above does not even include the third-party fine-tunes. For a more complete list in chronological order, check this link by Troyanovsky. Another list is LLM Explorer.
Open Source vs Open Weights
Developers are now starting to adopt the term “open weights” instead of “open source” to refer to LLMs released to the public. This is because of the trend of LLMs having only their weights available but not the data nor methodology used in training. It is therefore important to clarify and distinguish the terminologies [Link]. Throughout the remainder of this post, I’ll describe them as “open” instead of “open-source”.
Why use open large language models?
The primary reasons are customizability, uncensorship, and privacy. Cost is another, but using open LLMs does not automatically equate to reduced expenses.
Open LLMs are around 1 year behind closed LLMs in terms of proficiency. On the other hand, lot’s of progress are happening as I write. Guodong Zhao chronicles notable fine-tune releases here. Maxime Labonne graphed the Arena ELO ratings of open-weight LLMs, as seen below, gradually narrowing the gap between them and close-source models.
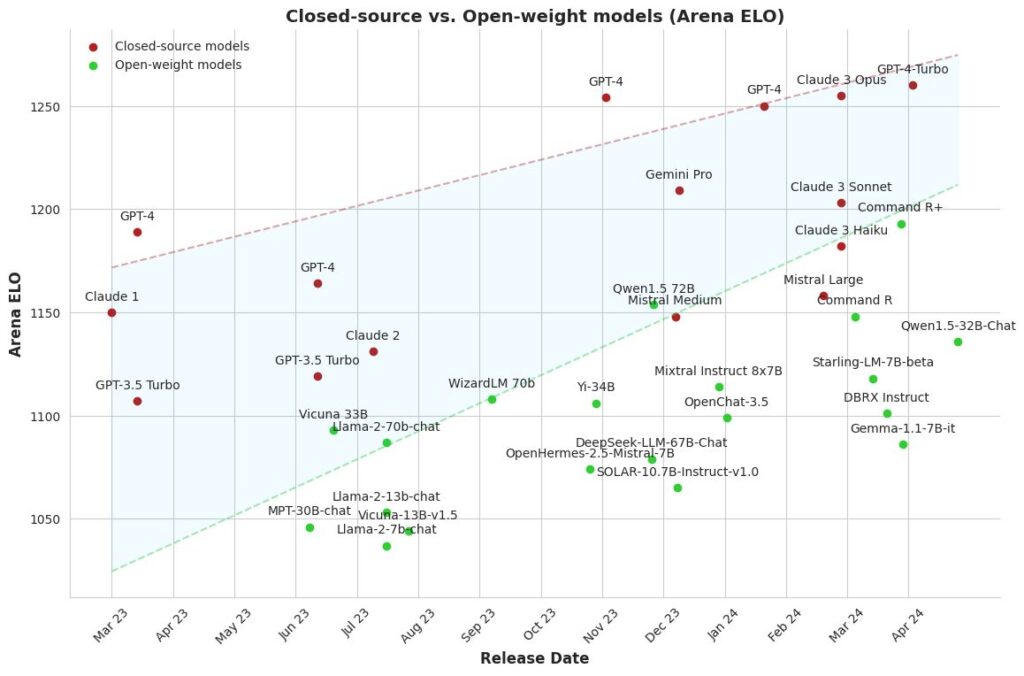
The Economics of Open-Source LLMs
Competition and optimization in LLMs have contributed to the rapidly declining cost of inference [Link]. One thing to note is that using open LLMs do not automatically mean cheaper.
Skanda Vivek analyzed the economics of large language models in his two articles:
- LLM Economics: ChatGPT vs Open-Source (Apr, 2023)
- The Economics of Large Language Models (Aug, 2023)
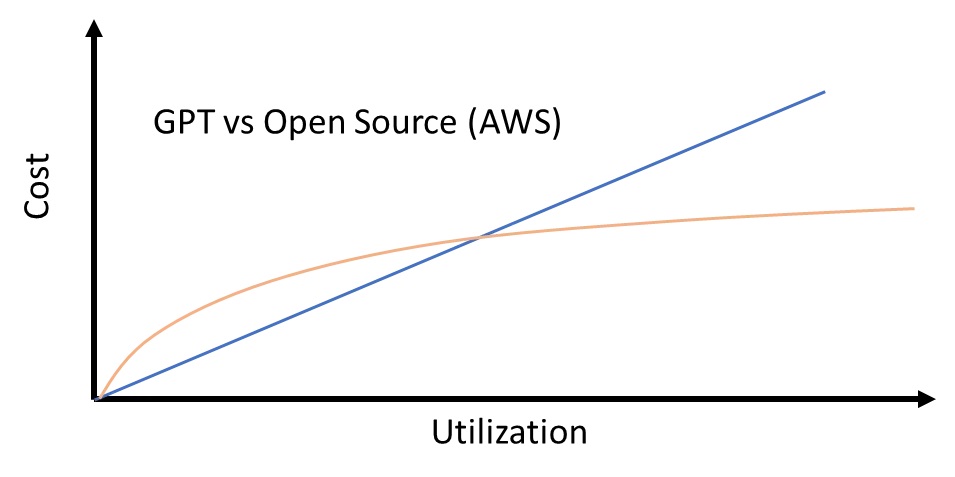
In short, it depends on your daily active users. For a small amount of users, it’s cheaper to use the inference APIs from providers. Nevertheless, there is a certain threshold where deploying an open LLM in the cloud is cheaper. Check the current pricing for LLM APIs using these calculators: DocsBot and YourGPT.
Even if the cost of inference were to drop to zero, there will always be a use case for local open models: they address the issue of privacy and security.
More references:
- Comparison & Cost Analysis: Should we go with open-source or closed-source LLMs? (Jan, 2024)
- Open Source vs. Closed Models: The True Cost of Running AI (Nov, 2023)
Understanding the naming scheme
LLM names have not yet been standardized. As such, we have these cryptic names that sound worse than Intel’s CPU naming scheme. Video reference here.
The Core Components
- Model name – the main identifier. It can be the company name, a brand name, an animal, or whatever.
- Parameter Count – can be thought of as the “brain size” of the model. In general, higher means better (but not always!) but also requires more expensive hardware to load and run.
- Version Number – notice that a lot of LLMs have version numbers that look like v0.X. Seems like many people adopted this scheme to reduce user expectation and indicate that the model is in the early access state.
If the model name only consists of the components above, it is likely that it is a base model (ex. Meta-Llama-3-70B, Mistral-7B-v0.3, Qwen1.5-7B)
Additional Suffixes
- Mixture of Experts (MoE) – a class of transformer model consisting of a router and a certain number of “experts”. (ex.
Mixtral-8x7B-v0.1) More info. - Fine-Tuning – a word to describe how the model was fine-tuned (ex. Instruct, Chat, RP, DPO)
- Context Length – can be 4K, 8K, 16K, 32K, or more. If not indicated, you can check the model’s
<strong>config.json</strong>file in Hugging Face and look for the value ofmax_position_embeddings. This is only a rule-of-thumb though. It’s not always the case. - Quantization Format –
GGUF,GGML,GPTQ,AWQ,EXL2, etc. - GGUF weight encoding scheme –
Q8_0,Q6_K,Q5_K_M,IQ4_XS,Imatrix, etc.
If the name does not specify any quantization format, then it is in full-precision FP16 or FP32.
What is Quantization
Quantization is a technique to reduce the computation and memory requirements to run a model [Link]. The goal is to allow users to run a model on lower-end hardware with an acceptable quality degradation. Read more about quantization here and here. Popular quantization formats are:
GGUF – GPT-Generated Unified Format. The successor to the GGML format. It allows models to run on both CPU and GPU. This means low-end devices can run high-parameter models. Which GGUF is right for me?
GPTQ – Post-Training Quantization for GPT Models. GPU only.
AWQ – Activation-aware Weight Quantization. GPU only.
EXL2 – ExLlamaV2. GPU only.
Two well-known individuals who create quantized models are TheBloke and LoneStriker.
Further reading
- A detailed comparison between
GPTQ,AWQ,EXL2,q4_K_M,q4_K_S, andload_in_4bit[link] (Oct. 2023) - Which Quantization Method is Right for You? [Link] (Nov. 2023) by Maarten Grootendorst.
- LLM Comparison/Test: Llama 3 Instruct 70B + 8B HF/GGUF/EXL2 [Link] (April 2024) by Wolfram Ravenwolf.
- Llama 3 quant comparison [Link] (May 2024) by matt-c1
Knowing all the information above, the burning question is: Which format should you choose? Assuming you want to run a 70B model, then the order of priority is:
- Full precision (FP16 or FP32)
EXL2>AWQ>GPTQ.GGUF. Use the largest parameter model that fits in your GPU. However, do some testing to check if there is too much degradation for your use case.
It is still recommended to test different formats of the same model yourself to see if they perform as expected. Quantization is an evolving field, and some quantized models uploaded to Hugging Face might not perform well for your use case.
Which Large Language Model Should I Use?
LLM releases are so frequent that the rankings change a lot. 1 month in real-world time is like several months in the AI industry. The ones I recommend will be outdated in just a few months. Bleeding-edge models and updated rankings are always popping up. Check out r/LocalLLaMa and LLM Explorer to see what’s currently trending.
Open models are typically 1-year behind proprietary models in terms of performance. Don’t expect them to be better than the latest GPT, Gemini, or Claude iteration. The most popular leaderboard is LMSYS Chatbot Arena. For open-source, there is the Open LLM Leaderboard. Other popular leaderboards exist in this list. Below are some task-specific leaderboards:
For coding:
- Aider LLM Leaderboards
- ProLLM Coding Assistant Benchmarks
- Big Code Models Leaderboard
- EvalPlus Leaderboard
For creative writing and uncensored models:
- Uncensored General Intelligence Leaderboard
- LLM Creativity Benchmark
- EQ-Bench Creative Writing
- NeoEvalPlusN Benchmark
Some things to consider:
- Choosing an LLM depends on your use case. The best LLM for coding is likely not the best for creative writing.
- Models that rank high in leaderboards might not perform well in your specific use case. It’s best to look at the rankings and read reviews about each to get a feel of the general consensus among human evaluators. And of course, try them yourself.
- Some models are significantly worse in a non-English language
- User froggeric, in his testing, does not recommend GGUF quantization smaller than Q4 for creative writing [link].
- For creative writing and role-playing, you’ll need high context length and no censorship. Read more about uncensored models in this post (May, 2023) by Eric Hartford.
I prepared a table for two hardware configurations. These models are by no means the best, but I’ve used them for a while. If you have better hardware, then check the leaderboard and choose whatever fits in your constraints.
[Updated, September 18, 2024]
| Category | 12GB VRAM (RTX 3060) | 24GB VRAM (RTX 3090) |
| General Purpose | Meta-Llama-3.1-8B-Instruct-GGUF | gemma-2-27b-it-GGUF |
| Code Generation | gemma-2-9b-it-GGUF | <a href="https://huggingface.co/bartowski/Codestral-22B-v0.1-GGUF">Codestral-22B-v0.1-GGUF</a> |
Use NyxKrage’s LLM Model VRAM Calculator to check if a model will fit in your GPU.
Other recommendations based on parameter count:
- 8B- Meta-Llama-3.1-8B-Instruct
- 12B- Mistral-NeMo-12B-Instruct
- 22B- Mistral-Small-Instruct-2409
- 27B- gemma-2-27b-it
- 35B- c4ai-command-r-08-2024
- 70B- Meta-Llama-3.1-70B-Instruct
- 103B- c4ai-command-r-plus-08-2024
- 123B- Mistral-Large-Instruct-2407
- 141B- WizardLM-2-8x22B
- 230B- DeepSeek-V2.5
- 405B- Meta-Llama-3.1-405B-Instruct
A large parameter quantized model or a small parameter unquantized model?
This question is asked a lot. Given the same hardware requirements, should you choose a large parameter quantized model (ex. 70B_Q2_K) over a small unquantized model (8B)? The answer: the output will be better, but the model will run slower. Only do this if speed is not a factor. The graph below shows the perplexity of different quantized models of LlaMA 2 variants.
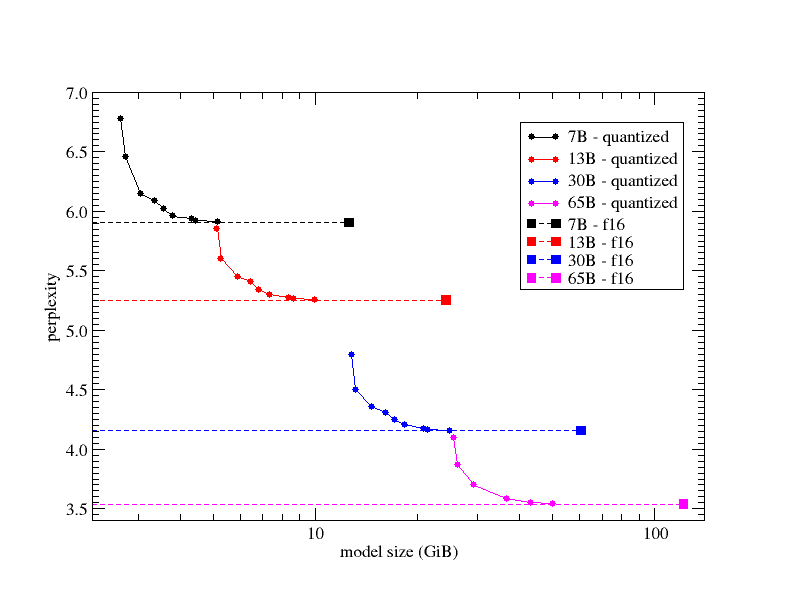
Running Open Large Language Models Locally
You need a backend to run a language model, and a frontend to interact with it. Or you can start from scratch and create your own backend/frontend on top of the inference frameworks listed. Watch this video (Feb, 2024) by bycloud for a quick video overview.
| Function | Tools |
| Inference and Optimization Frameworks | LLaMA.cpp, vLLM, ExLlamav2 |
| Backend | ollama |
| Backend with Frontend | Oobabooga, KoboldAI United, KoboldCpp |
| Frontend | Open WebUI, SillyTavern |
| Standalone app | LM Studio, Jan.ai |
| Mobile app | Layla Lite, Maid, Chatter UI, LLM Farm |
- Beginners usually start with LM Studio, which is closed source. I recommend this as well if you’re starting out. Easy to set up, download models, and experiment. Familiarize yourself with jargons like the different
GGUFquants, GPU offloading layers, prompt formatting, context length, temperature, etc. - I personally use Oobabooga because it has a simple chatting interface and supports
GGUF,EXL2,AWQ, andGPTQ. - Ollama, KoboldCpp, and LM Studio (which are built around llama.cpp) do not support
EXL2,AWQ, andGPTQ. - Open WebUI as a frontend is nice. It feels like ChatGPT and allows uploading documents and images as an input (if the model supports it).
- SillyTavern is a popular frontend in the role-playing community.
- Jan.ai is the open-source alternative to LM Studio.
- I recommend choosing looking into each one of these tools and see which fits your preferences.
There is a tool called pinokio that let’s you install most of the popular AI tools without the hassle of setting up Python virtual environments for each. You might want to check that one out.
Deploying Open LLMs in the Cloud for Inference
What if you don’t have a GPU powerful enough to run models? You’ll need to deploy them in the cloud. Check out this LLM hosting list at LLM Explorer. Replicate is a popular cloud platform for inference APIs and LLM hosting. It is simple and accessible but can be expensive. For alternatives, many folks recommend RunPod.io and Vast.ai. They beat the competition in terms of pricing, but they are less reliable according to some reviewers. There’s also the big tech trio: Azure, Amazon Sagemaker, and Google Cloud Platform. For inference-only, TogetherAI is a popular choice.
Here are more references and comparisons to aid your decision making:
- Top 10 Serverless GPU vendors (Apr. 2024) by Hazal Şimşek
- Cloud GPUs for Deep Learning (Mar. 2024) by Cem Dilmegani
- Top 10 Cloud GPU Providers in 2024 (Mar. 2024) by Cem Dilmegani
- Cloud GPUs (Oct. 2023) by Sergey Karayew and Charles Frye.
- The State of Serverless GPUs – Part 2 (Nov, 2023) Aishwarya Goel & Nilesh Agarwal
- The State of Serverless GPUs (Apr. 2023) by Aishwarya Goel & Nilesh Agarwal
- The Ultimate Guide to Cloud GPU Providers by Paperspace
- Deep Learning GPU Benchmarks (2023) by Lambda Labs
How do you decide on which cloud GPU to use? Tim Dittmers made an extensive guide on deep learning GPUs. Below is a flowchart that will help you make a decision right away:
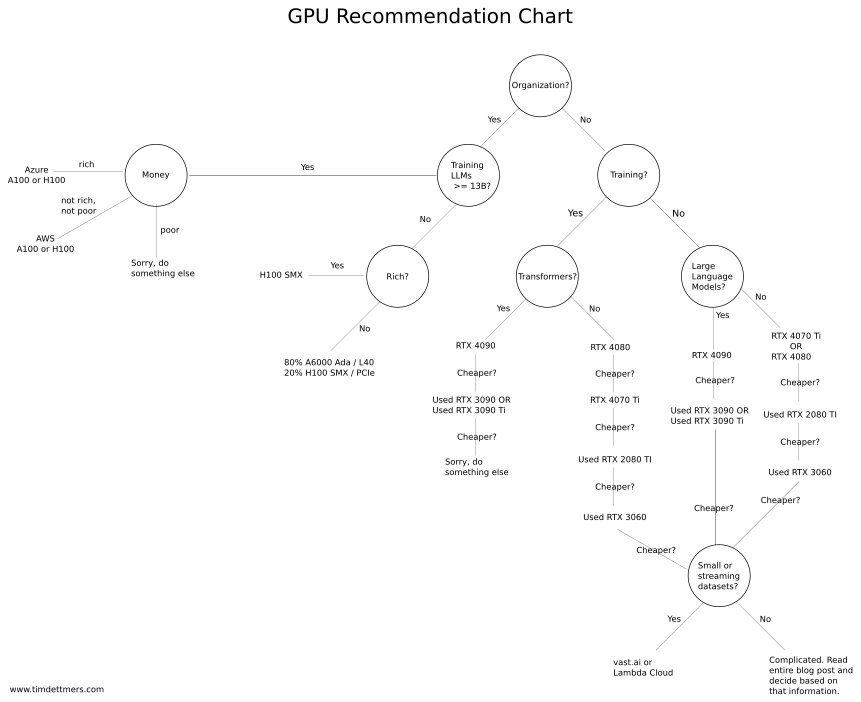
“I’m broke. I don’t have a powerful machine, and I don’t have money to spend on these cloud platforms. What do you recommend?” Use Google Colab to get started with free NVIDIA T4 GPU usage, 16GB VRAM. Install ollama, use ngrok to expose ollama server from colab to the web. Video tutorial here and here.
Where do I go from here?
The next step is to look into fine-tuning, the process of adapting an LLM to a specific task or dataset. You can also explore more topics about Generative AI:
- Generative AI for Beginners by Microsoft
- Generative AI Handbook (June 2024) by William Brown



One Reply to “Running Open Large Language Models Locally”
Comments are closed.